この記事はこういう方向けに書いてます。
- pythonをある程度やっている
- GoogleSheetsAPIの初期設定が済んでいる
- プログラムでスプレッドシートを操作したい
- 重複する行の削除がしたい
- フィルター機能をつけてさらに並び替えた状態にしたい
初期設定はこちらのページがわかりやすくて参考になります。
この方の記事には何度も助けられてます。神w
前置き(長いので飛ばしていいですw)
こんにちは、プログラムを始めてそろそろ1年経過しそうです。
とりあえず、ちょっと動かせればいいかなと思って初めてみたPythonですが
思いのほか沼にずっぽしとハマってしまいました。
たまにコード書くのがしんどいこともありますが、初心者の頃わからないことだらけで投げてたリファレンスなんかをゆったり読んでみると
「ああこういうことか、なあんだ」というものが多くあり、自分も成長したなぁと思う次第であります。

上の画像のスプレッドシートはプログラム3か月目ぐらいで作ったものになります。
もともとただの表だったものが色々な方から案を頂いてこのような見やすい表まで仕上げることができました。
現在も更新を続けてます。
無料オンラインサロン「副業ラボ」にて今の所は限定公開してますので気になる方はコメントかメールください。
こちらの表を作るにあたってスプレッドシート操作めちゃくちゃ使いました。
データフレームをそのまま表にする方法、フォーマットを整える方法、行を交互に色付けする方法など
一番難しかったのは条件付き書式です。(商材ごとの最高値にハイライトをつけている所)
これは自分でもよく出来たなぁと思いますw
ここで本題の「JSON形式でrequestを送る方法」というものが当時本当にわからなすぎて避けてたんです。
ジェイソンとか怖いし!金曜日に襲われるし?!
まあ、最近またスプレッドシート操作を扱いたかったので改めてやってみたらあんま難しくなかったよってことで。
日本語の解説も少ないので備忘録も兼ねて記しておきます。
誰かの役に立ちますように!
重複している行を削除する
コード
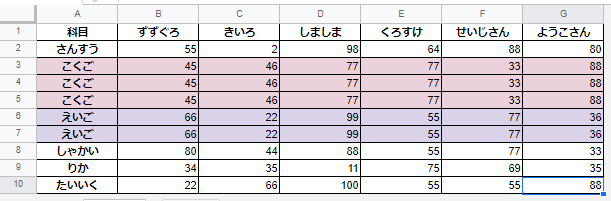
重複している行に色付けしてます。
from oauth2client.service_account import ServiceAccountCredentials
import gspread
TEST_SHEET_KEY = "スプレッドシートキーを入力してください"
SCOPES = ["https://spreadsheets.google.com/feeds", "https://www.googleapis.com/auth/drive"]
CREDENTIALS_PATH = "秘密鍵があるPATHを入力してください"
# 認証
def gspread_auth(SPREADSHEET_KEY):
credentials = ServiceAccountCredentials.from_json_keyfile_name(CREDENTIALS_PATH, SCOPES)
gs = gspread.authorize(credentials)
wb = gs.open_by_key(SPREADSHEET_KEY)
return wb
# 重複した行を削除する
def delete_duplicates(wb, sheet_id, last_row_num, last_col_num):
req = {
"requests": [
{
"deleteDuplicates": {
"range": {
"sheetId": sheet_id,
"startRowIndex": 0,
"endRowIndex": last_row_num,
"startColumnIndex": 0,
"endColumnIndex": last_col_num
},
# # 重複判定の範囲設定
# "comparisonColumns": [
# {
# "sheetId": sheet_id,
# "dimension": "COLUMNS",
# "startIndex": 0,
# "endIndex": 2
# }
# ]
}
}
]
}
wb.batch_update(req)
print('delete_duplicates success!!')
def main():
wb = gspread_auth(TEST_SHEET_KEY)
ws = wb.worksheet('シート1')
sheet_id = ws._properties['sheetId']
last_row_num = ws.row_count
last_columns_num = ws.col_count
delete_duplicates(wb, sheet_id, last_row_num, last_columns_num)
if __name__ == '__main__':
main()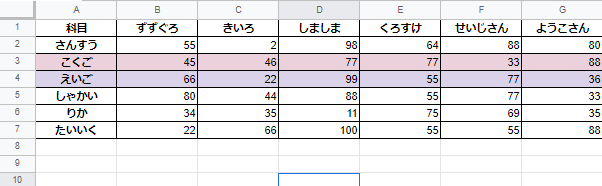
実行後、重複行が削除されています。
ざっくり解説
# 認証
def gspread_auth(SPREADSHEET_KEY):
credentials = ServiceAccountCredentials.from_json_keyfile_name(CREDENTIALS_PATH, SCOPES)
gs = gspread.authorize(credentials)
wb = gs.open_by_key(SPREADSHEET_KEY)
return wb
def main():
wb = gspread_auth(TEST_SHEET_KEY)
まずgspread_auth(SPREADSHEET_KEY)で認証を行います。
ws = wb.worksheet('シート1')
sheet_id = ws._properties['sheetId']apiにrequestを送る時にシートIDが必要なのでこちらをws._properties[‘sheetId’]で取得しておきます。
last_row_num = ws.row_count
last_columns_num = ws.col_count今回データ入力部分全てに適用させたいので、データが入力されているシートの最終行と最終列を取得します。
requestsの中身
req = {
"requests": [
{
"deleteDuplicates": {
"range": {
"sheetId": sheet_id,
"startRowIndex": 0,
"endRowIndex": last_row_num,
"startColumnIndex": 0,
"endColumnIndex": last_col_num
},
# # 重複判定の範囲設定
# "comparisonColumns": [
# {
# "sheetId": sheet_id,
# "dimension": "COLUMNS",
# "startIndex": 0,
# "endIndex": 2
# }
# ]
}
}
]
}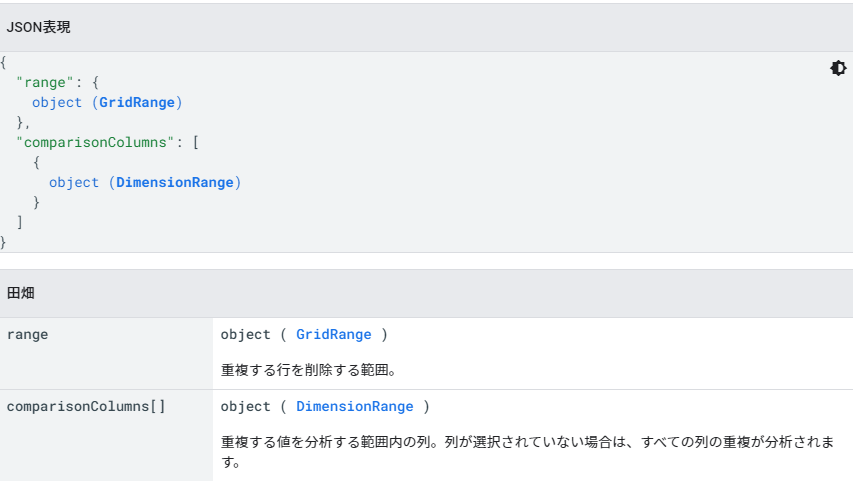
今回はすべての列の値を分析対象にしたのでコメントアウトしてあります。(デフォルトでは すべての列の値が分析対象になってます)
どの列の値をキーにして削除するかの設定は”comparisonColumns”で設定できるようです。
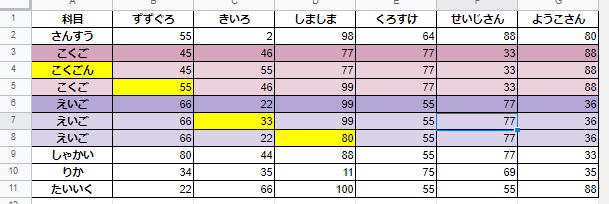
こんなかんじの1~4列目の値が違うものを用意しました。
値を変えた部分は黄色に塗ってます。
次はコメントアウトを外して実行します。
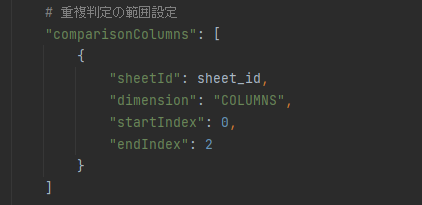
こうなりました。
”endIndex”に2と入力すると、2列目までのデータが一緒なら重複していると見なされ削除されるようです。
フィルターをかけて降順に並び替える
GASを使ってフィルターをかける方法もあります。
こちらで解説していますのでよろしければお読みください。
コード
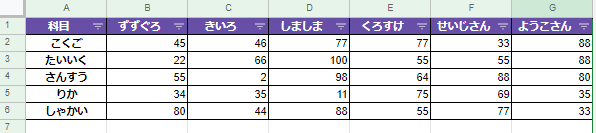
実行前
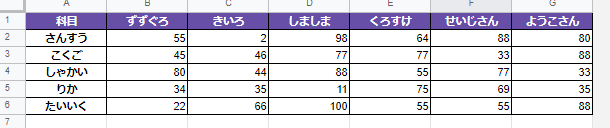
最終列をキーに降順で並び替えます。
def set_filter_sorted_descending(wb, sheet_id, last_row_num, last_col_num):
# フィルターをセットする
req = {
"requests": [
{
"setBasicFilter": {
"filter": {
"range": {
"sheetId": sheet_id,
"startRowIndex": 0,
"endRowIndex": last_row_num,
"startColumnIndex": 0,
"endColumnIndex": last_col_num
},
"sortSpecs": [
{
# 降順で並び替える
"sortOrder": "DESCENDING",
"dimensionIndex": last_col_num-1,
}
],
}
}
}
]
}
wb.batch_update(req)
print('set_filter_sorted_descending success!!')実行後
“sortOrder”: “DESCENDING”
“dimensionIndex”: last_col_num-1
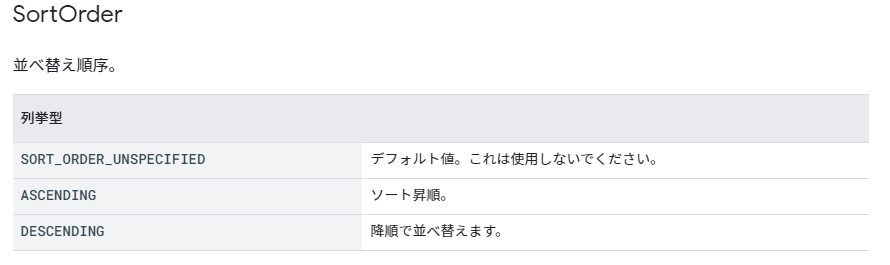
sortSpecsで並び替えの設定ができるようです。
dimensionIndex でキーとなる列を指定します。
このindex番号は0から始まってますので-1をしてます。
last_col_num(-1をしない)で実行すると原因がわかりにくいエラーメッセージ吐かれますので注意です。
gspread.exceptions.APIError: {'code': 500, 'message': 'Internal error encountered.', 'status': 'INTERNAL'}

コメント